
💥 ¿Por qué 1 millón de fans de Bad Bunny colapsaron Ticketmaster?
¿Ticketmaster caído por las entradas de Bad Bunny? Analizamos el colapso de su sistema y las soluciones de arquitectura para gestionar picos de tráfico masivo.

Mayo de 2025. España entera vibra. Bad Bunny anuncia las fechas de su esperadísima gira por el país.
A las 13:00 CET del 8 de mayo, se abren las preventas en Ticketmaster.es y LiveNation.es.
En cuestión de minutos, la euforia se transforma en frustración. Errores "500 Internal Server Error" o "503 Service Unavailable" inundan las pantallas.
Las colas virtuales se vuelven infinitas, con reportes de más de un millón de usuarios concurrentes intentando acceder.
El sistema, simplemente, colapsó.
No era la primera vez; la historia se repetía, recordando fiascos anteriores con artistas como Taylor Swift.
Pero, ¿qué sucede exactamente bajo el capó para que gigantes como Ticketmaster y Live Nation se arrodillen ante la demanda?
Identifica dónde y cómo aplicar IA desde hoy con el GPT Arquitecto IA completamente gratis.
Lo recibes en el primer email que te mando al suscribirte
⚡ Contexto rápido
Este post resume la arquitectura detrás de estos gigantes de la venta de entradas y los puntos críticos que fallaron estrepitosamente ante la avalancha de tráfico. Al final, encontrarás referencias para profundizar aún más.
🏰 El Problema de la Demanda Masiva
Había una vez un mundo donde conseguir entradas para un concierto implicaba hacer cola física durante horas, a veces días.
Con la llegada de internet, la promesa era la comodidad y la eficiencia. Ticketmaster, fundado en 1976, y Live Nation, surgido mucho después y fusionado con Ticketmaster en 2010, digitalizaron este proceso.
Durante años, sus sistemas evolucionaron desde infraestructuras on-premise, con servidores físicos que tenían una capacidad finita y conocida, hacia arquitecturas más modernas.
Se pensaba que la nube y sus promesas de escalabilidad infinita serían la solución definitiva. Sin embargo, eventos de altísima demanda, como los conciertos de Bad Bunny o Taylor Swift, demostraron que incluso las arquitecturas cloud más robustas tienen un límite si no se diseñan y gestionan para picos verdaderamente extremos
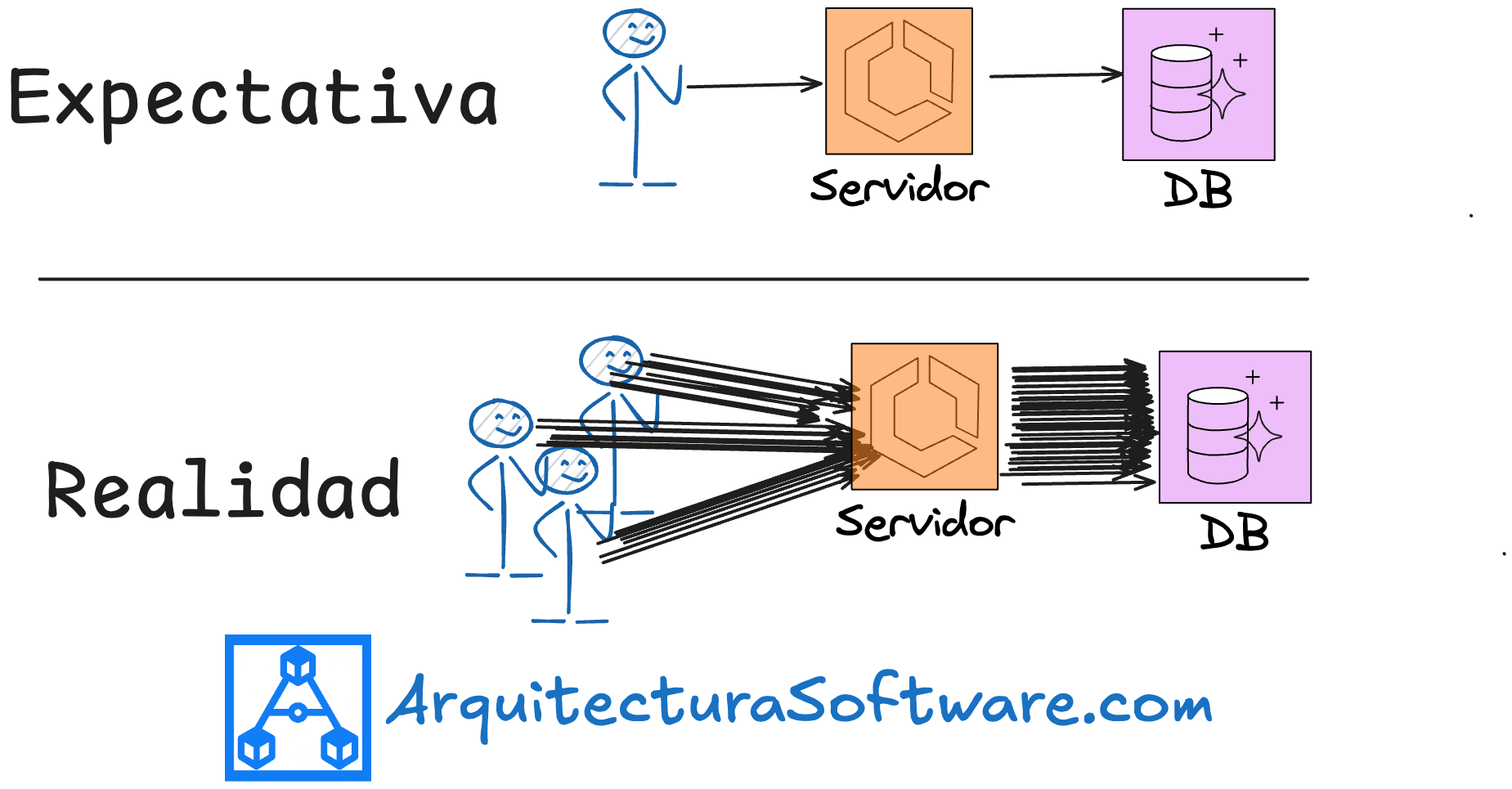
⚙️ La tormenta de usuarios
La migración a la nube (principalmente AWS) y el uso de microservicios ofrecieron mayor agilidad y capacidad de escalado horizontal en comparación con sistemas monolíticos antiguos.
Problema 1: Picos impredecibles y subestimados. Aunque se esperara alta demanda, la magnitud real, con millones de usuarios y miles de millones de peticiones en pocas horas (como los 3.5 mil millones para Taylor Swift), superó las previsiones y la capacidad de autoescalado instantáneo.
Problema 2: Cuellos de botella transaccionales. La selección y bloqueo de asientos es inherentemente una operación crítica que requiere consistencia y bloqueos en la base de datos, difícil de escalar horizontalmente bajo una avalancha de escrituras.
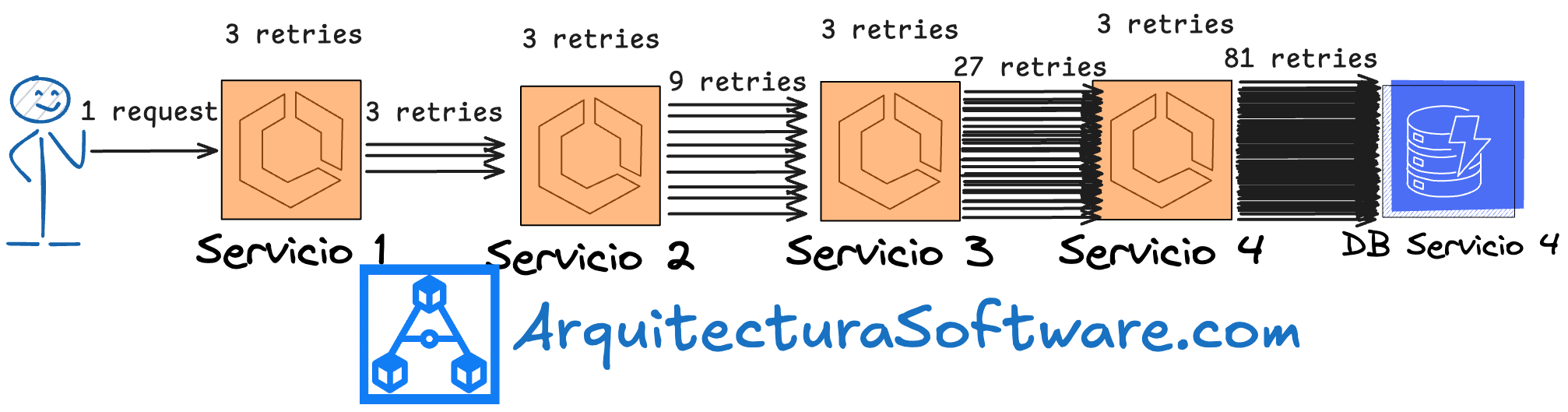
Problema 3: El efecto "retry storm". Usuarios y bots frustrados recargando la página sin cesar, multiplicando la carga sobre sistemas ya estresados, creando un círculo vicioso. Lo que para el usuario es 1 petición, para un sistema múltiples niveles en profundidad pueden ser muchas por los retries:

🗺️ Modelos Comunes para Gestionar Avalanchas de Tráfico
Cuando se enfrenta a una demanda masiva y repentina, existen varios patrones arquitectónicos y estrategias generales que los sistemas pueden emplear:
Escalado Elástico Agresivo: Diseñar para que la infraestructura (servidores, bases de datos, balanceadores) pueda multiplicarse rápidamente ante picos, y reducirse después.
Sistemas de Cola Avanzados: No solo una "sala de espera", sino colas de mensajes desacopladas (como Kafka o SQS) que procesan peticiones a un ritmo que el backend pueda soportar.
Rate Limiting y Throttling en el Edge: Bloquear o ralentizar peticiones excesivas directamente en el CDN o API Gateway antes de que lleguen a los servicios principales.
Sistemas federados, cada región opera su propio cluster con réplica de datos parcial. No sirve de mucho en los conciertos porque la mayoría de usuarios son de la misma región.
Enfoques de cola descentralizada, colas de mensajes por subsistema que regulan el flujo hacia servicios críticos. Actúan de buffer para proteger los servicios por el alto número de peticiones.
🎯 El Enfoque de Ticketmaster/Live Nation: Microservicios en la Nube y Capas de Caché
Ticketmaster y Live Nation utilizan una arquitectura de microservicios distribuida, predominantemente en AWS, orquestando sus servicios con Kubernetes (EKS). Complementan esto con múltiples capas de caché.

Piensa en ello como una gran ciudad preparada para un festival. Tienes diferentes distritos especializados (microservicios para autenticación, inventario, pagos). Las autopistas de entrada (API Gateways, Load Balancers) intentan distribuir el tráfico. Hay puestos de información rápida en las afueras (CDN como Fastly para contenido estático) y dentro de la ciudad (Varnish, ElastiCache para datos dinámicos de acceso frecuente).
El problema surge cuando todas los API Gateways y Load Balancers se colapsan simultáneamente y los microservicios clave, como el de venta de entradas en la base de datos, no dan abasto.
Tu backend es tan escalable como el microservicio que menor escala maneja.
🧩 Componentes Clave (y sus Puntos Débiles)
1. ☁️ Infraestructura Cloud y Orquestación (AWS EKS)
¿Para qué sirve? Proporcionar la base escalable para todos los servicios. Permite desplegar, gestionar y escalar aplicaciones en contenedores.
Cómo funciona:
Las aplicaciones se empaquetan en contenedores (Docker).
Kubernetes (a través de Amazon EKS) orquesta estos contenedores, manejando el despliegue, el autoescalado (añadiendo o quitando réplicas de servicios según la carga) y la salud de los servicios.
Servicios de AWS como EC2 (para los nodos de Kubernetes), API Gateway (para exponer APIs), Lambda (para funciones serverless), RDS (bases de datos relacionales), MSK (Kafka gestionado), SNS/SQS (para mensajería) son utilizados extensivamente.
Tecnologías clave: AWS (EKS, EC2, S3, API Gateway, Lambda, RDS, MSK, SNS/SQS), Kubernetes, Docker.
A pesar del autoescalado, la velocidad y la magnitud del pico de Bad Bunny (o Taylor Swift) pueden superar la capacidad de reacción del sistema si no está pre-provisionado masivamente o si los límites de escalado no son suficientemente altos, especialmente para componentes con estado como las bases de datos.
Es por ello que hacer warmup de estos sisteams y escalarlos antes de que llegue la demanda es importnate.
2. 🌍 Gestión de Tráfico y Caché (Fastly CDN, Varnish)
¿Para qué sirve? Reducir la latencia entregando contenido desde ubicaciones cercanas al usuario y disminuir la carga en los servidores de origen.
Cómo funciona:
Fastly (CDN): Almacena contenido estático (imágenes, CSS, JavaScript) en servidores distribuidos globalmente (edge). Cuando un usuario pide este contenido, se sirve desde el nodo más cercano.
Varnish Cache: Se sitúa delante de los servidores de origen. Cachea respuestas de peticiones dinámicas que son comunes o no cambian tan frecuentemente. El error "No healthy backends" indica que Varnish no encontraba servidores de origen funcionales a los que pasar la petición.
Tecnologías clave: Fastly, Varnish.
Estas capas de caché son vitales, pero para operaciones de venta de entradas (ver disponibilidad, seleccionar asiento, comprar), muchas peticiones son inherentemente dinámicas y deben llegar al origen. Si el origen colapsa, el caché no puede hacer milagros para estas operaciones.
3. 🎟️ Sistema de Cola Virtual y "Verified Fan"
¿Para qué sirve? Intentar gestionar el flujo masivo de usuarios hacia el sistema de compra y filtrar bots.
Cómo funciona:
Verified Fan: Los usuarios se registran con antelación. Ticketmaster selecciona un subconjunto y les envía códigos de acceso únicos para la preventa. La idea es reducir la competencia con bots.
Sala de Espera Virtual: Unos minutos antes de la venta, los usuarios entran a una sala.
Cola Virtual: Al comenzar la venta, se asigna un puesto en la cola. Una vez dentro, pueden seleccionar entradas.
Tecnologías clave: Lógica de aplicación customizada, posiblemente usando servicios de colas de AWS (SQS) o Kafka internamente para gestionar el flujo de usuarios admitidos.
En la práctica, durante el evento de Bad Bunny y Taylor Swift, el sistema de Verified Fan fue insuficiente; millones de usuarios (con y sin código) y bots intentaron acceder.
Las colas virtuales se saturaron, y el propio sistema de colas se convirtió en un cuello de botella o falló, expulsando usuarios o mostrando tiempos de espera irreales.
4. 🗄️ Bases de Datos y Gestión de Inventario (RDS, ElastiCache, MongoDB)
¿Para qué sirve? Almacenar de forma persistente la información de usuarios, el inventario de entradas (qué asientos están disponibles, reservados, vendidos) y procesar las transacciones de compra.
Cómo funciona:
Bases de Datos Relacionales (MySQL/Oracle, vía Amazon RDS): Se usan para datos transaccionales críticos, como la venta de entradas, debido a sus propiedades ACID que garantizan la consistencia. Aquí es donde ocurren los bloqueos para asegurar que una entrada no se venda dos veces.
MongoDB: Utilizado para datos no transaccionales o menos críticos que requieren más flexibilidad.
Amazon ElastiCache (Redis/Memcached): Se usa como una capa de caché en memoria para acelerar el acceso a datos frecuentemente leídos (ej: disponibilidad general de secciones, no el asiento específico).
Tecnologías clave: Amazon RDS (MySQL, Oracle), MongoDB, Amazon ElastiCache.
El mayor cuello de botella aquí es la escritura concurrente en la base de datos relacional para el inventario. Cada intento de seleccionar o comprar un asiento implica una transacción. Con cientos de miles de personas intentándolo a la vez, la base de datos se satura de peticiones de escritura y bloqueos, ralentizando todo el proceso. Este es un desafío clásico en sistemas de alta concurrencia.
Pero claro, todo es un tradeoff. De cara al usuario, es mejor que hayan tiempos de espera altos a que varios usuarios compren entrada para el mismo asiento.
5. 💸 Integración con Pasarelas de Pago y Dependencias Externas
¿Para qué sirve? Procesar los pagos de las entradas.
Cómo funciona:
Una vez que el usuario selecciona las entradas y va a pagar, el sistema de Ticketmaster se comunica con servicios de terceros (pasarelas de pago como PayPal, Stripe, o sistemas bancarios locales).
Estos servicios externos procesan la transacción y devuelven una confirmación o un error.
Tecnologías clave: APIs de pasarelas de pago (PayPal, Stripe, RedSys en España, etc.).
Si estas pasarelas de pago externas se ven también sobrecargadas por el volumen de peticiones provenientes de Ticketmaster (y posiblemente de otros comercios sufriendo picos), pueden empezar a fallar o a responder lentamente. Esto provoca errores en el checkout, y los usuarios vuelven a intentarlo, añadiendo más carga.
✨ Lecciones Aprendidas del colapso de TicketMaster
En resumen:
La demanda desbordó la capacidad: Más de un millón de usuarios concurrentes para Bad Bunny en España fue simplemente demasiado.
Efecto dominó: Fallos en un componente (ej: base de datos de inventario) pueden tumbar otros servicios dependientes.
Los bots no ayudaron: A pesar de Verified Fan, el tráfico de bots infló artificialmente la carga, comportándose como un ataque DDoS.
El "retry storm": La incapacidad de rechazar peticiones excedentes o fallar rápido llevó a que los usuarios (y bots) bombardearan los servidores hasta el colapso.
Escrituras en BBDD, el gran cuello de botella: La naturaleza transaccional de la venta de entradas es difícil de escalar para escrituras masivas.
Caché con límites: Varnish y Fastly ayudaron, pero no pudieron evitar que las peticiones dinámicas esenciales saturaran los backends ("No healthy backends").
Throttling insuficiente: Faltaron mecanismos más agresivos para limitar la cantidad de peticiones que llegaban al núcleo del sistema.
Dependencias de terceros: Las pasarelas de pago pueden ser otro punto de fallo bajo carga extrema.
Comunicación crucial: La falta de información clara durante el caos aumenta la frustración.
Como conclusión, hay desafíos que son inherentes del problema a resolver. Si 1 millón de personas quieren el mismo asiento, da igual que la venta de entradas sea en físico o de manera online: Es un caos.
Diseñar sistemas escalables no trata solo sobre la tecnología a utilizar, sino las features de la aplicación. Quizás el problema no es solo la sobrecarga de algunos servicios, sino la manera de vender entradas online en un día y hora concretos que genere esos picos de tráfico
👋 PS – ¿Quieres dominar el system design y entender cómo se construyen (y a veces se rompen) los sistemas a gran escala?
📚 Referencias:
Ticketmaster System Architecture and Design insights:
AWS Case Studies (genérico sobre migraciones a la nube): aws.amazon.com (Buscar casos de Ticketmaster o Live Nation si existen públicos)
Fastly Customer Story (sobre migración a su CDN): fastly.com
SlideShare presentations on Ticketmaster's architecture (buscar por "Ticketmaster architecture"): slideshare.net
Informes de las caídas (Bad Bunny en España):
El Confidencial: "El aviso de Varnish que detecta por qué se cayó Ticketmaster..." elconfidencial.com (Buscar el artículo específico)
20 Minutos: "Caos en la preventa de Bad Bunny..." 20minutos.es (Buscar el artículo específico)
Análisis Post-Mortem (Taylor Swift y otros):
Ticketmaster Blog/Business Page (para declaraciones oficiales sobre el caso Swift): business.ticketmaster.com, blog.ticketmaster.com
LearningDaily.dev (análisis técnicos de la caída de Swift): learningdaily.dev (Buscar "Ticketmaster Swift")
RunSignup Blog (comparativas de carga en eventos): info.runsignup.com

📝 Otros artículos de interés

![👨💻[INFOGRAPHIC] The 10 times in history that software engineers were to be replaced](https://substackcdn.com/image/fetch/$s_!vm_2!,w_140,h_140,c_fill,f_webp,q_auto:good,fl_progressive:steep,g_auto/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F9e6c5116-8d2a-478a-a0cb-01ecbeae119c_800x2000.jpeg)


👏 Aplauso semanal
Aquí algunos artículos que me han gustado esta última semana:
DeepWiki: ¿La nueva aliada para entender repositorios complejos? por CarPerDev . Una herramienta de IA que genera documentación interactiva a partir de repositorios de GitHub para facilitar su comprensión.
Una nueva era de automatización por David González. La evolución de la automatización a través de una pirámide de 4 niveles, desde las reglas fijas tradicionales hasta los agentes de IA autónomos.
Cómo envían emails los CEOs por Alberto Abel Sesmero. Analiza el estilo de comunicación por email de CEOs tecnológicos como Jeff Bezos o Steve Jobs, extrayendo lecciones sobre inmediatez, humildad y transparencia.
El tróspido futuro de Web Reactiva por Daniel Primo. Reflexiona sobre el futuro de su proyecto, compartiendo sus cifras, motivaciones y planes de cambio, como enfocarse más en el análisis de contenido y la creación de proyectos prácticos.
Las 5 cosas que separan al freelance que vive bien del que sobrevive por Jorge Jorge Bosch Alés. Resume los 5 principios clave que generan el 80% de los resultados para tener éxito como freelance, empezando por resolver un problema específico para un público concreto.
🙏 Una última cosa antes de que te vayas:
Siempre estoy trabajando para hacer esta newsletter aún mejor.
¿Podrías tomarte un minuto para responder una encuesta rápida y anónima?
Nos vemos en el próximo correo,
Fran.
Muchas gracias por la mención Fran!
Pedazo de newsletter te has currado 👏