
Así se degradó la calidad de Claude por culpa de tres bugs solapados
Tres bugs degradaron las respuestas de Claude durante semanas. Analizamos la arquitectura rota y y cómo Anthropic puede prevenirlo en el futuro.

Claude era fiable, rápido y preciso. Lo usaban millones, desde su web y vía Amazon Bedrock o Google Vertex AI. Pero algo empezó a fallar.
Algunos veían respuestas en tailandés, otros código roto. Muchos decían que ya no era el mismo. Otros, que seguía perfecto.
Nadie entendía por qué.
Ahí comenzó una investigación que llevó semanas. Y lo que encontraron fue inesperado: no era un bug, sino tres. Tres fallos independientes, solapados, que se reforzaban entre sí.
Identifica dónde y cómo aplicar IA desde hoy con el GPT Arquitecto IA completamente gratis.
Lo recibes en el primer email que te mando al suscribirte
📌 Contexto rápido
Este post resume la arquitectura para servir peticiones de Claude, el LLM de Anthropic, y cómo tres errores técnicos solapados degradaron su calidad de respuesta durante semanas.
Al final encontrarás referencias técnicas y ejemplos reales. Y si te interesa construir sistemas de este nivel, cada semana comparto un nuevo caso con diagramas, decisiones reales y plantillas listas para aplicar.
Bug 1: Sticky routing

Claude tenía un sistema de enrutamiento “inteligente” con algunas decisiones arriesgadas:
Separaba los servidores según el tamaño de contexto. Los que soportaban ventanas de 1M tokens estaban en un pool distinto a los normales.
Usaba sticky routing. Una vez que tu conversación era atendida por un servidor, todas tus siguientes peticiones iban al mismo nodo.
No detectaba desbalances en producción. Confiaba en pruebas previas, sin monitoreo continuo de calidad.
Un cambio en el load balancer hizo que algunas requests normales terminaran ahí por error.
Ese desvío afectaba la calidad. Los servidores de contexto largo estaban optimizados para otra cosa, y las respuestas se volvían incoherentes. Como había sticky routing, los usuarios quedaban atascados en ese pool.
En su pico, el 16% del tráfico iba al lugar equivocado.
Bug 2: Tokens corruptos en plena inferencia
Una mala configuración en los servidores TPU provocó que Claude generara tokens con probabilidades erráticas. Aparecían caracteres tailandeses en prompts en inglés, o código con errores obvios de sintaxis.
No era aleatorio: una optimización de performance hizo que algunos tokens improbables se colaran con puntuaciones altas. Eso rompía la coherencia.
El bug afectó a Opus y Sonnet durante una semana. No se desplegó en Bedrock ni Vertex AI.
Bug 3: Sampling roto por compilación

Claude usaba “approximate top-k” para generar tokens rápido en TPU. Pero al refactorizar ese módulo, apareció un bug en el compilador XLA:TPU que rompía la precisión.
En lugar de devolver los tokens más probables, a veces omitía el mejor. Y no siempre era reproducible. El error dependía del batch size o del orden interno de las operaciones.
El fix fue claro: abandonar el approximate top-k y volver al exacto. Menos rápido, pero mucho más confiable.
Claude usa una arquitectura monolítica con multihardware
Claude funciona como una capa unificada que orquesta múltiples clusters y plataformas de hardware. Piensa en ello como un McDonalds, tiene restaurantes en muchos países distintos, pero todos deben preparar el mismo plato con el mismo sabor.
Cada petición se enruta según la disponibilidad y el tipo de contexto, pero el objetivo es que el usuario nunca sepa si se usó GPU, TPU o Trainium. Esa equivalencia es clave, pero también introduce mucha complejidad.
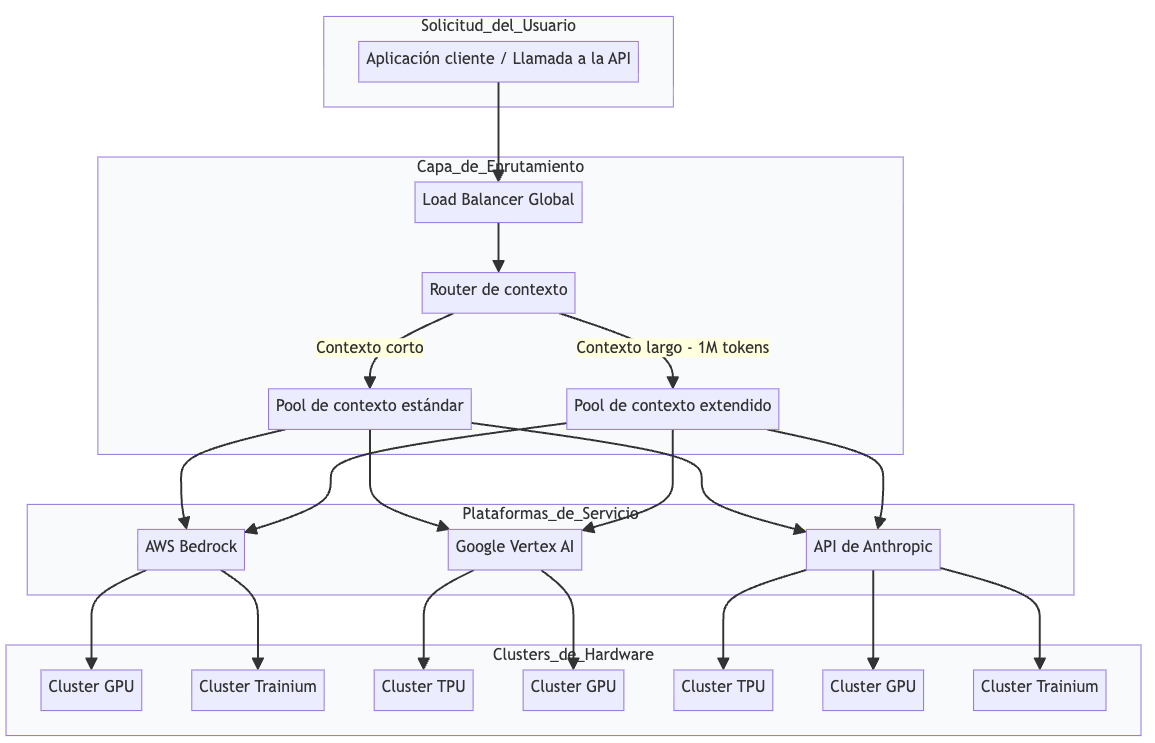
Desglose de componentes clave
1. Enrutador de contexto
¿Para qué sirve? Decide a qué servidor enviar cada solicitud, según el tipo de modelo y el tamaño del contexto.
Cómo funciona
Detecta si la petición requiere soporte para 1M tokens.
Selecciona el pool de servidores correspondiente
Aplica afinidad de sesión para mantener coherencia.
Tecnologías clave: load balancer interno, sticky routing, headers HTTP para flags de contexto.
2. Clusters de inferencia
¿Para qué sirve? Ejecutan el modelo Claude sobre el hardware disponible.
Cómo funciona
El modelo se divide entre múltiples chips (TPU o GPU).
Cada chip procesa una parte del cálculo.
Los resultados se agrupan para formar la respuesta final.
Tecnologías clave: TPUs de Google, GPUs NVIDIA, AWS Trainium, XLA compiler, distribución tensorial.
3. Algoritmo de sampling
¿Para qué sirve? Determina qué token generar en cada paso.
Cómo funciona
Calcula probabilidades para miles de tokens.
Usa top-k o top-p sampling para filtrar candidatos.
Selecciona aleatoriamente uno dentro de los mejores.
Tecnologías clave: approximate top-k (ahora reemplazado), precisión bf16/fp32, xla_allow_excess_precision.
4. Evaluador de calidad
¿Para qué sirve? Detecta degradaciones en las respuestas del modelo.
Cómo funciona
Corre pruebas automatizadas con prompts conocidos.
Compara salidas actuales con versiones anteriores.
Genera alertas si hay cambios estadísticamente significativos.
Tecnologías clave: eval harness interno, benchmarks sintéticos, métricas de coherencia y diversidad.
5. Plataforma de terceros
¿Para qué sirve? Expone Claude como servicio a través de AWS Bedrock y Google Vertex AI.
Cómo funciona
Traduce llamadas de terceros al API de Anthropic.
Usa pools de hardware diferenciados.
Puede operar con versiones específicas o rezagadas del modelo.
Tecnologías clave: integración multi-cloud, API gateway, sincronización de versiones.
En resumen: lo que pasó

Tres bugs independientes degradaron Claude al mismo tiempo.
Uno era de ruteo de contexto, otro de configuración en TPUs, y otro en el compilador XLA.
La combinación hacía que algunos usuarios vieran degradaciones graves, mientras otros no.
Los errores persistieron semanas porque las evaluaciones internas no los detectaban.
Claude opera sobre infraestructura heterogénea con alto riesgo de inconsistencia si no se valida cada cambio.
Se abandonaron optimizaciones arriesgadas (como approximate top-k) para garantizar calidad.
Ahora hacen evaluaciones continuas en producción, no solo antes del deploy.
Se reforzó la colaboración con usuarios para detectar errores más rápido.
¿Y cómo pueden mejorar esta arquitectura para introducir cambios más rápido y con más confianza?

Una arquitectura robusta no basta si los errores pasan desapercibidos. Anthropic aprendió por las malas que no basta con hacer canary deployments o medir throughput.
Para detectar degradaciones reales, necesitas:
Métricas centradas en la experiencia del usuario. No solo latencia o éxito HTTP, sino indicadores de calidad de respuesta por tipo de prompt y modelo.
Alarms sensibles y específicas. Que detecten cambios sutiles en output quality, character entropy o fallas sintácticas, no solo caídas completas. Sobre todo, cuando introduzcas un nuevo A/B test, quieres segmentar la métrica para ver si la nueva experiencia la degrada
Feedback reproducible. Claude tenía limitaciones por privacidad, pero sin trazabilidad, es casi imposible aislar el bug. Deben permitir que usuarios hagan opt-in a compartir información de diagnóstico, que los usuarios puedan elegir compartir un chat no-anonimizado para bug report.
Capacidad de inspeccionar degradaciones por cohortes. Qué porcentaje de usuarios están viendo respuestas rotas, y si vienen del mismo pool o hardware. No tenían trazabilidad en una arquitectura muy heterogénea y con muchos componentes
Test de regresión en tiempo real. Prompts fijos y prompts nuevos comparados contra versiones previas del modelo, con validación automática. Que corran contra cada nuevo cambio y que sean canary tests que corran en producción todo el rato para detectar degradaciones.
Detectar errores como estos no depende solo del código. Depende de cómo midas lo que entrega tu sistema en producción. Calidad percibida, no solo uptime.
📬 ¿Te gustaría diseñar infra como esta?
👋 PS – ¿Quieres dominar el system design?
Suscríbete para recibir cada semana un caso real de arquitectura explicado con diagramas, decisiones técnicas y checklists listos para aplicar. Ya somos más de 20,000 ingenieros aprendiendo juntos.
📚 Referencias
📝 Otros artículos de interés




Las imágenes más fancy son generadas con IA, las que se vean feas son las que he generado yo :)