
▪️◼️⬛ Cómo escalar tu base de datos relacional
Las bases de datos relacionales fallan al escalar. Esta guía te ayuda a elegir la estrategia correcta desde indexado hasta sharding sin hacer sobreingeniería.

Las bases de datos relacionales nos dan poder, estructura y consistencia.
Pero cuando empiezan a flaquear bajo una gran escala, es fácil tomar la decisión equivocada, como crear índices sin medir, o hacer sharding demasiado pronto.
En los últimos años, he trabajado en infraestructura de migración de bases de datos, pruebas de failover y depuración de rendimiento en varios equipos.
Lo que he aprendido es esto: escalar no se trata tanto de trucos ingeniosos, sino de conocer tu carga de trabajo, elegir el compromiso adecuado y entender el eslabón más débil de tu sistema.
Identifica dónde y cómo aplicar IA desde hoy con el GPT Arquitecto IA completamente gratis.
Lo recibes en el primer email que te mando al suscribirte
⭐ En este artículo, aprenderás
Cuándo usar el escalado vertical antes de sumergirse en la complejidad distribuida
Qué mejoras de bajo esfuerzo generan un alto impacto (como la indexación y el caching)
Cómo escalar lecturas y escrituras de forma independiente con replicación y sharding
Técnicas para gestionar grandes conjuntos de datos con particionamiento y archivado
Cómo elegir la estrategia correcta usando un marco de decisión práctico
🏗️ #1 Introducción: por qué es difícil escalar bases de datos relacionales
Las bases de datos relacionales son geniales hasta que dejan de serlo. Funcionan bien desde el principio para la mayoría de las startups, pero a medida que aumenta la carga, alcanzas los límites rápidamente. Especialmente con RDBMS tradicionales como PostgreSQL o MySQL, que nunca fueron diseñados para una escala masiva o escrituras multirregión.
Puedes solucionar el problema añadiendo más hardware (escalado vertical) o dividiendo los datos entre máquinas (escalado horizontal). Ambas opciones conllevan costes y complejidad. Las decisiones de escalado también afectan a la fiabilidad, el rendimiento y la capacidad de mantenimiento de tu equipo a largo plazo.
Imagina que tu instancia de PostgreSQL empieza a dar timeouts en horas punta. ¿Replicación? ¿Indexación? ¿Sharding? Este artículo te ayudará a elegir el siguiente paso correcto.
📈 #2 Escalado vertical: la opción obvia pero limitada
El escalado vertical es simple. Añade más CPU, memoria o SSD a tu servidor de base de datos. Normalmente funciona, hasta que deja de hacerlo.
Si la CPU está al máximo, aumenta el tamaño de la instancia. Si el problema son las IOPS, cambia a volúmenes provisionados. La ventaja: no hay cambios en la aplicación. La desventaja: siempre hay un límite. Y la factura es cada vez más cara.
He visto equipos posponer soluciones adecuadas durante demasiado tiempo por confiar en el escalado vertical. Una vez, tuve un PostgreSQL con consultas que tardaban demasiado. Se podría haber pensado que tener una instancia más potente ayudaría, pero la instancia existente ya estaba infrautilizada. El problema de raíz eran planes de consulta ineficientes y la falta de índices para consultas costosas.
Usa el escalado vertical al principio. Pero a medida que el tráfico crece o tu conjunto de datos se hace más grande, se convierte en una tirita temporal en lugar de una solución a largo plazo.
🧮 #3 Indexación: la victoria fácil del rendimiento
Los índices suelen ser la forma más rápida de solucionar problemas de rendimiento sin tocar el código. Funcionan creando atajos para que la base de datos encuentre los datos.
Tienes opciones: B-tree (por defecto), hash, GIN para búsqueda de texto completo, BRIN para datos de series temporales, índices parciales para cubrir casos específicos. He tenido casos en los que añadir un simple índice en user_id redujo la latencia de los joins en 10 veces. Algunas bases de datos como PostgreSQL incluso permiten crear índices funcionales, como por ejemplo indexar una columna en lower_case cuando la columna original no está en minúsculas, pero algún patrón de consulta utiliza la función LOWER().
Pero nada es gratis. Los índices ralentizan las escrituras y aumentan el almacenamiento. También necesitan mantenimiento. En mi equipo el año pasado, notamos que un par de índices nunca se usaban. Pudimos eliminarlos tras revisar nuestros patrones de consulta.
Usa índices cuando tu problema sea la latencia de lectura y el patrón de acceso sea predecible. Evita indexar ciegamente cada columna: monitoriza primero los planes de consulta.
📚 #4 Replicación: escalar lecturas y garantizar alta disponibilidad
La replicación te permite descargar las lecturas y mejorar la disponibilidad. Copias los datos de un primario a una o más réplicas. Hay diferentes modos: asíncrono, síncrono, semisíncrono, y cada uno intercambia consistencia por rendimiento.
Piensa en tu primario como un chef principal. Las réplicas son asistentes que duplican su trabajo. Te ayuda a servir a más clientes, pero puede que reciban los pedidos con unos segundos de retraso.
No se trata solo de escalar, sino también de fiabilidad. El año pasado, probando el failover de las instancias, encontré formas de reducir el tiempo de failover de 45 a 3 minutos teniendo una réplica de lectura lista para convertirse en el líder en el momento en que el líder fallara. Nunca quieres que tu instancia de escritura falle... hasta que lo hace y prefieres tener 3 minutos de inactividad en lugar de 45.
La replicación ayuda en cargas de trabajo intensivas en lectura y en configuraciones de alta disponibilidad (HA). Solo recuerda: las escrituras siguen yendo al primario, y el lag de replicación puede provocar lecturas de datos obsoletos. Diseña en consecuencia.
🧠 #5 Caching: reducir la presión en la BD con intermediarios más rápidos
Si la replicación se encarga de la escala de lectura, el caching se encarga de la frecuencia de lectura. Se trata de almacenar los datos de acceso frecuente (hot data) más cerca del usuario, a menudo en memoria con Redis, Memcached o AWS DAX.
Aquí es donde quieres saber si tienes más lecturas o escrituras. Si tu carga es intensiva en lecturas, puedes cachear estos datos porque apenas cambian.
Pero el caching es una trampa si no piensas bien en la invalidación. Podrías acabar con bugs de cara al usuario porque los TTL no estaban bien ajustados o las actualizaciones no invalidaban correctamente.
Usa caching cuando los datos cambien lentamente y el throughput de lectura sea importante. Sé explícito sobre cómo se refresca y qué sucede en los fallos de caché (cache misses).
🧾 #6 Desnormalización: intercambiar pureza por rendimiento
La desnormalización consiste en duplicar datos entre tablas para evitar joins en el momento de la lectura. Es un compromiso: velocidad a cambio de duplicación de datos.
Esto funciona bien para analítica, dashboards o cualquier cosa donde el rendimiento importe más que la consistencia. Pero tienes que pensar detenidamente en las rutas de actualización.
Solo desnormaliza cuando esté respaldado por una propiedad clara y rutas de escritura sólidas. No lo hagas solo para “facilitar las consultas”.

📊 #7 Vistas materializadas: precomputar consultas costosas
Cuando te enfrentas repetidamente a agregaciones costosas, las vistas materializadas son una victoria. Calculas una consulta compleja una vez y reutilizas el resultado.
Es rápido y predecible. Pero puede quedar obsoleto si no se refresca correctamente. Necesitas una estrategia clara sobre cuándo y cómo refrescar, especialmente si los datos provienen de muchas fuentes.
Genial para dashboards, herramientas de BI o trabajos por lotes (batch jobs). Solo no olvides que es una instantánea (snapshot), no el estado en vivo.
🪵 #8 Particionamiento: dividir tablas grandes en trozos más pequeños y manejables
El particionamiento divide tablas grandes en piezas lógicas basándose en una columna como la fecha o la región. Es imprescindible para datos de series temporales, logs o cualquier cosa que crezca linealmente.
Imagina tener una tabla de logs con más de mil millones de filas. Una vez que la particionas por mes, las consultas pasan de minutos a segundos. Archivar datos antiguos también se volvió trivial. Puedes moverlos fuera de tu base de datos a una infraestructura de almacenamiento en frío (cold storage), como AWS S3 Glacier.
Pero añade complejidad al esquema. Tienes que gestionar la creación de particiones y evitar una distribución desigual de los datos.
Usa el particionamiento cuando el tamaño de la tabla perjudica el rendimiento de las consultas o la limpieza. Especialmente cuando las consultas se centran en datos recientes y guardas los datos antiguos por cumplimiento normativo y no para una funcionalidad del cliente.
🧩 #9 Sharding: escalado horizontal de escritura con datos distribuidos
El sharding es el jefe final del escalado de bases de datos. Divides los datos entre instancias, a menudo por un hash de una clave como user_id. Cada shard es como una base de datos independiente más pequeña.
Esto escala las escrituras y aísla la carga. Pero conlleva enormes costes. No hay transacciones globales. No hay joins entre shards. Migraciones complejas. Necesitas un enrutamiento de consultas inteligente y automatización.
Usa sharding solo cuando un único nodo de escritura es el cuello de botella y tus datos se segmentan de forma natural.
👉 Existen muchos algoritmos de sharding. Hazme saber en los comentarios si te interesa este tipo de contenido para seguir escribiéndolo.
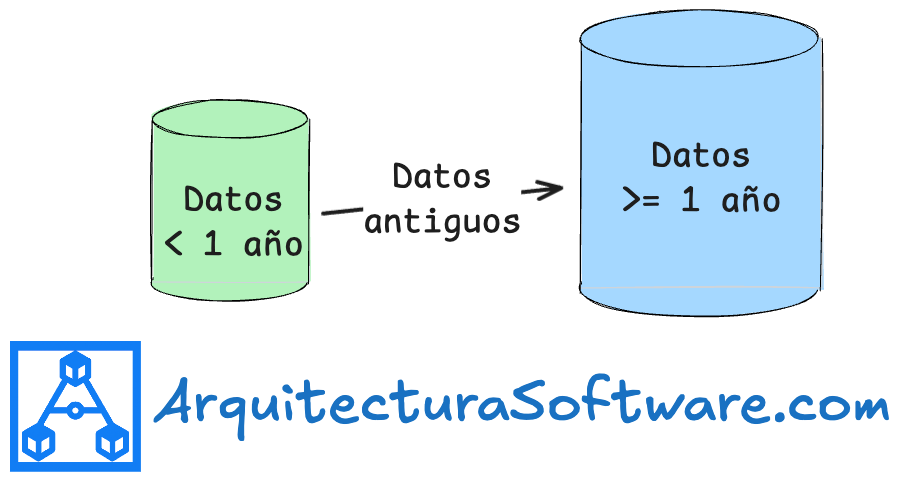
🧊 #10 Archivado: mantén la ruta crítica ligera
No necesitas todos los datos en línea. El archivado mueve los datos de acceso poco frecuente (cold data) a un almacenamiento más lento y barato. Mantiene tu base de datos principal rápida y ligera.
Por ejemplo, archiva los pedidos de más de dos años en S3 o en una base de datos separada. La base de datos activa se mantiene rápida. Los datos archivados siguen disponibles si es necesario, solo que su acceso es más lento.
En Amazon, esto surge a menudo. Los equipos suelen ignorar la limpieza y las bases de datos se sobrecargan. Sin embargo, cuando un equipo configura un almacenamiento en frío (cold storage) y algunas reglas de ciclo de vida para mover datos automáticamente, su factura se reduce considerablemente.
Archiva cuando tengas reglas de retención claras y un acceso poco frecuente. Construye rutas de rehidratación desde el principio para evitar sorpresas.
🛠️ #11 Técnicas avanzadas (bonus)
El pool de conexiones es higiene básica. Sin él, tu aplicación se colapsará a sí misma abriendo nuevas conexiones en cada petición. Usa siempre un pool.
La optimización de consultas significa usar EXPLAIN a menudo para identificar los patrones de acceso a datos, corregir joins ineficientes y reescribir consultas lentas.
Los patrones de lectura tras escritura (read-after-write) son importantes si usas caching o réplicas. Si tu aplicación lee datos obsoletos después de escribir, prueba con write-through caching o espera a que las réplicas se pongan al día. No puedes pensar en una base de datos sin pensar en la aplicación que la utiliza.
La replicación multirregión puede reducir la latencia, pero la coordinación global es difícil. Solo vale la pena cuando los usuarios abarcan continentes y la latencia es un factor clave.
🧭 #12 Marco de decisión: eligiendo la estrategia de escalado correcta
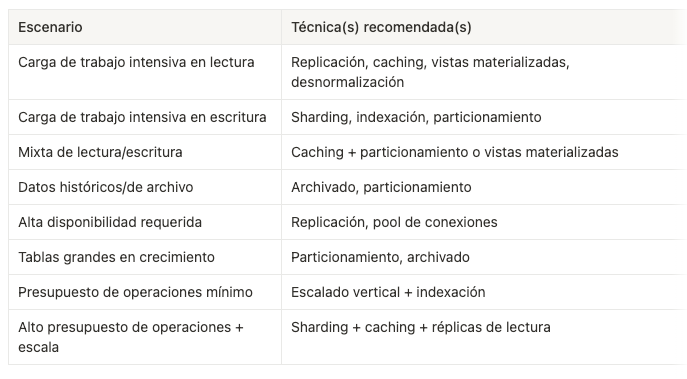
Checklist:
¿El cuello de botella es la CPU, la memoria o las IOPS?
¿Estás escalando lecturas, escrituras o ambas?
¿Necesitas consistencia fuerte o la consistencia eventual es suficiente?
¿Las consultas son lentas por el tamaño de los datos, una mala indexación o joins complejos?
¿Puedes hacer sharding por usuario, organización o alguna otra clave natural?
🎯 Conclusión
Escala por etapas. La mayoría de los sistemas no necesitan sharding ni vistas materializadas el primer día. Empieza con victorias sencillas como la indexación o el caching. Mide, y luego optimiza.
Invierte en observabilidad para saber dónde está sufriendo tu base de datos. Añade presión gradualmente e itera con un propósito.
El escalado no es una funcionalidad que “añades”. Es una negociación constante entre rendimiento, complejidad y mantenibilidad. Construye lo que tu sistema realmente necesita, no lo que parece impresionante.

📝 Otros artículos de interés




👏 Aplauso semanal
Aquí algunos artículos que me han gustado esta última semana:
DynamoDB global tables con consistencia fuerte: ¿cómo lo hicieron? por Marcia Villalba . Este artículo explica cómo Amazon DynamoDB logró una consistencia fuerte para las tablas globales multirregión, detallando las complejidades de ingeniería y la introducción de un journal multirregión.
El reto de parecer estúpido y estar bien con ello por Daniel Primo. Este artículo aborda la frustración y el sentimiento de "estupidez" que a menudo acompañan a los desarrolladores al enfrentarse a errores, proponiendo la aceptación de la ignorancia como motor de curiosidad y la importancia de equivocarse para progresar
🙏 Una última cosa antes de que te vayas:
Siempre estoy trabajando para hacer esta newsletter aún mejor.
¿Podrías tomarte un minuto para responder una encuesta rápida y anónima?
Nos vemos en el próximo correo,
Fran.