
Arquitectura de software de Roblox: cómo evolucionó tras 73 horas de downtime
Lecciones prácticas de resiliencia a hiperescala en Roblox. Arquitectura celular, activo-activo, service mesh y tooling para reducir el radio de impacto

TL;DR:
La arquitectura de software de Roblox pasó de un único centro de datos a un diseño con redundancia geográfica y células aisladas que contienen fallos.
La arquitectura celular reduce el radio de impacto y permite descartar y reconstruir una célula de forma automatizada.
Un service mesh con políticas de tráfico y límites de concurrencia evita que una petición problemática se propague entre células.
El tooling interno, IaC y prácticas de chaos engineering sostienen la resiliencia operativa día a día.
La migración se planificó por fases desde 2021 con objetivo de operación activo-activo y mejoras continuas.
Identifica dónde y cómo aplicar IA desde hoy con el GPT Arquitecto IA completamente gratis.
Lo recibes en el primer email que te mando al suscribirte

Contexto: la caída de 73 horas en octubre de 2021
Octubre de 2021. El universo de Roblox se apaga.
Durante 73 largas horas, la plataforma global que conecta a decenas de millones de personas en tiempo real queda en silencio. Un fallo aparentemente menor en un componente de un único centro de datos se propaga como un virus y provoca un colapso en cascada. El sistema, abrumado por reintentos automáticos, se rinde.
Para los ingenieros de Roblox no fue solo una caída. Fue el comienzo de una transformación de infraestructura con el objetivo de que un evento así no volviera a repetirse y que el metaverso de Roblox fuese más resistente a nivel estructural.
Este artículo resume la evolución de la arquitectura de Roblox desde su punto más frágil hasta su diseño actual y aporta ideas prácticas para tus propios sistemas.
El problema: vulnerabilidad por centralización y efecto dominó de reintentos
La arquitectura inicial funcionaba principalmente desde un único centro de datos activo. Esta centralización simplificaba la operación al principio y permitió crecer de forma controlada. Con la escala alcanzada apareció su talón de Aquiles.
Ventaja inicial
Operar un único clúster gigante es más sencillo y reduce variabilidad al inicio.
Problema de escala
Un fallo puntual tiene un impacto desproporcionado al no existir un plan B geográficamente independiente con conmutación rápida.
Efecto dominó
Servicios y clientes reintentaban de forma agresiva. Los reintentos sin control sobrecargaban componentes sanos y convertían una incidencia local en un apagón global.
El dolor de la caída de 73 horas justificó rediseñar con un objetivo claro. Reducir el radio de impacto y hacer que el sistema fuera capaz de absorber fallos sin colapsar.
Patrones de resiliencia a escala
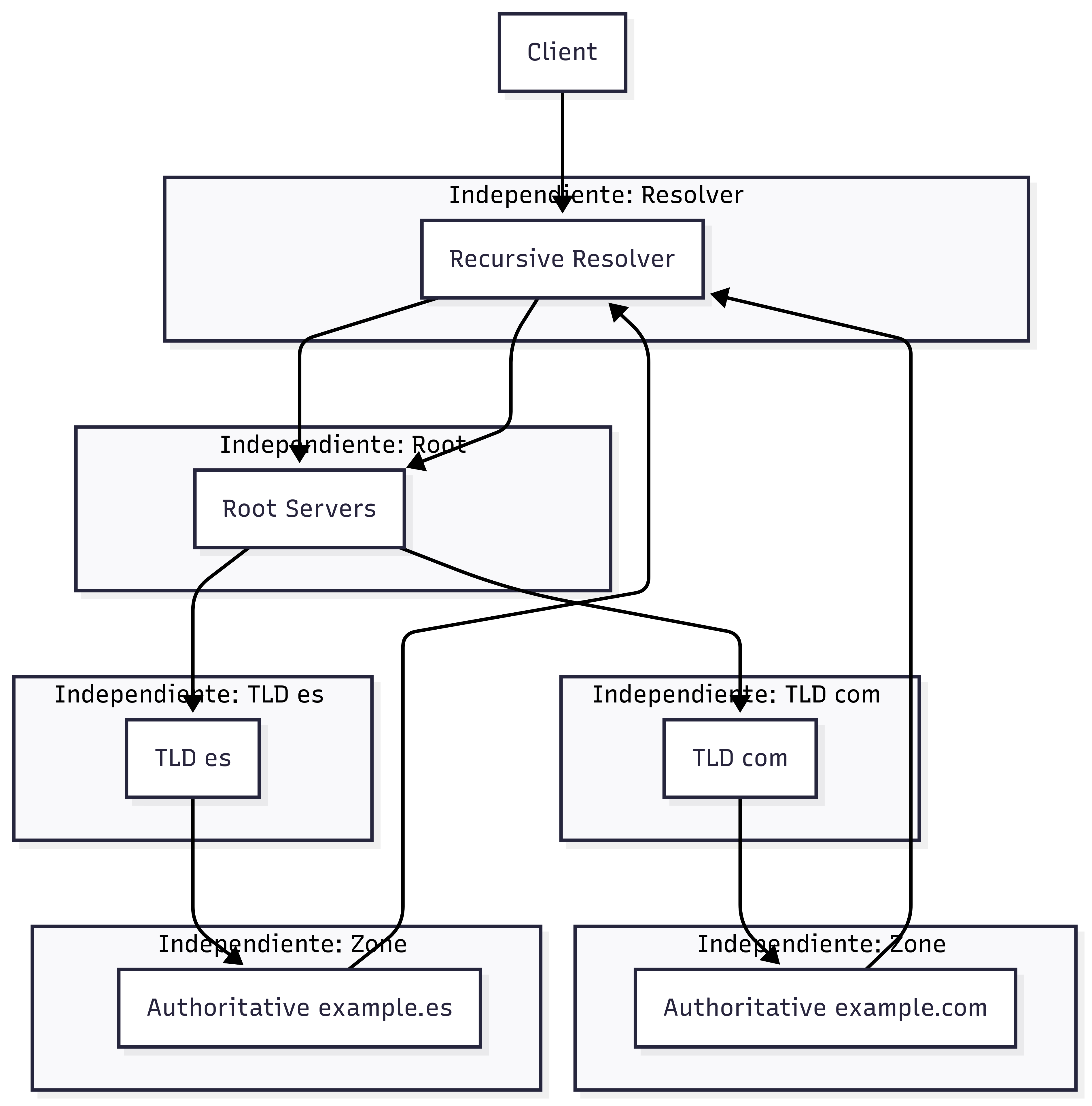
Federado
Sistemas independientes que se comunican entre sí. Como los DNS en la resolución de los dominios.
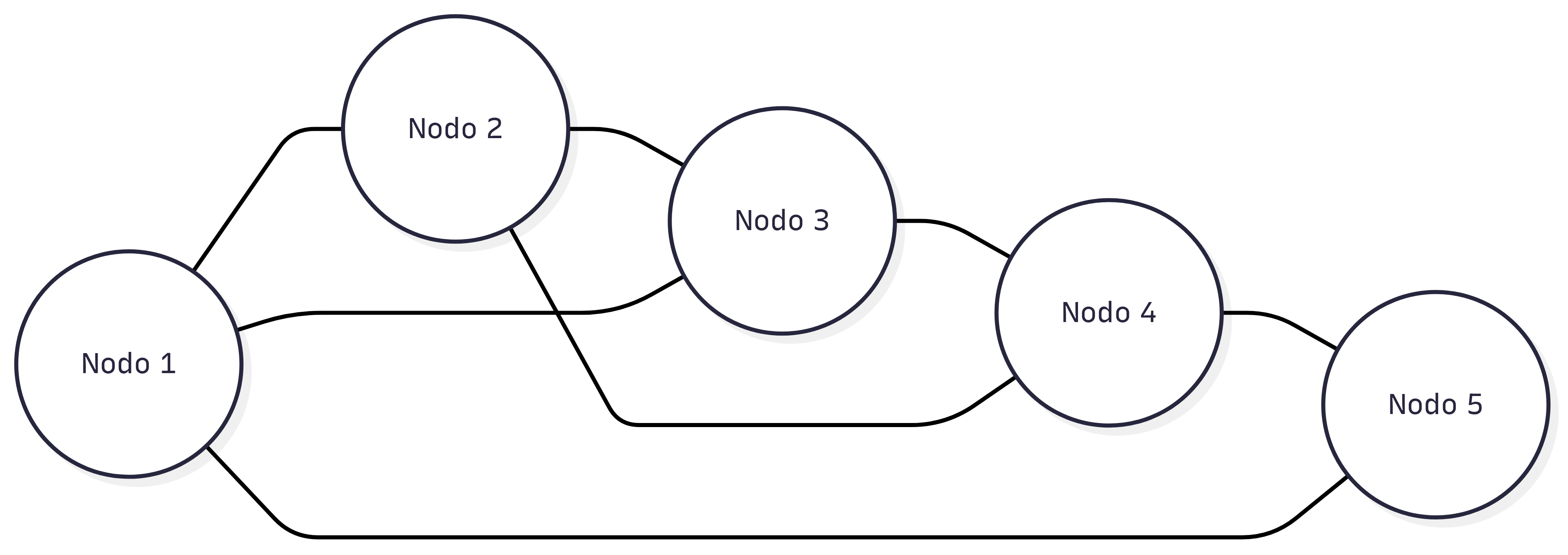
Peer to Peer
Todos los nodos son iguales y comparten carga y datos. Útil para distribución masiva y tolerancia parcial a fallos. Requiere control fino del enrutado y del estado.
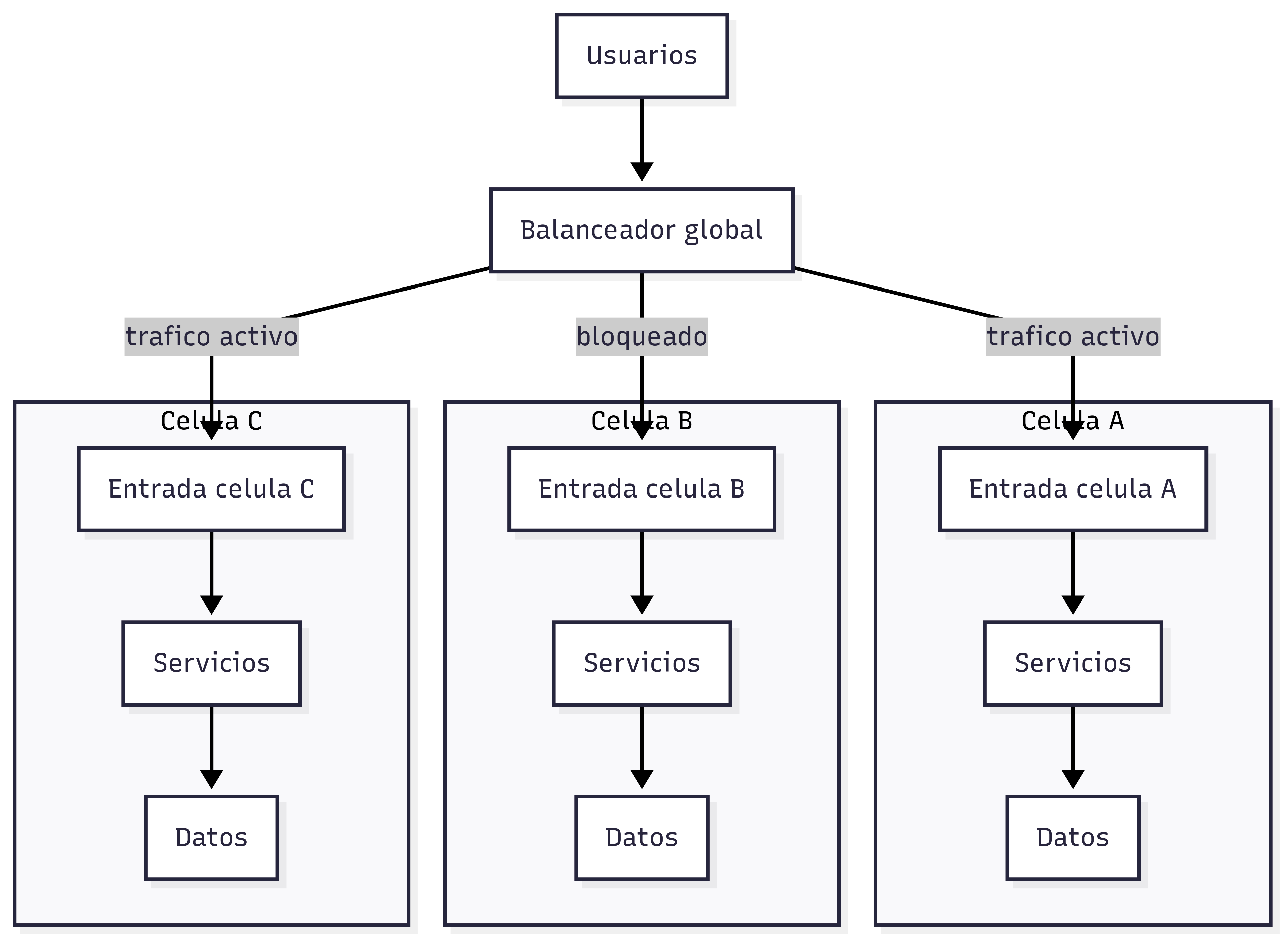
Arquitectura celular
El sistema se divide en réplicas idénticas y aisladas llamadas células. El tráfico se distribuye entre ellas y si una falla las demás siguen operando. Este patrón limita el alcance de un incidente y facilita la recuperación controlada.
Decisión: por qué Roblox adopta arquitectura celular
Roblox eligió arquitectura celular para contener fallos. La idea se inspira en el bulkhead pattern. Igual que un submarino se compartimenta para que una vía de agua no hunda toda la nave, una célula defectuosa se aísla sin afectar al resto.
Pilares de la arquitectura de software de Roblox
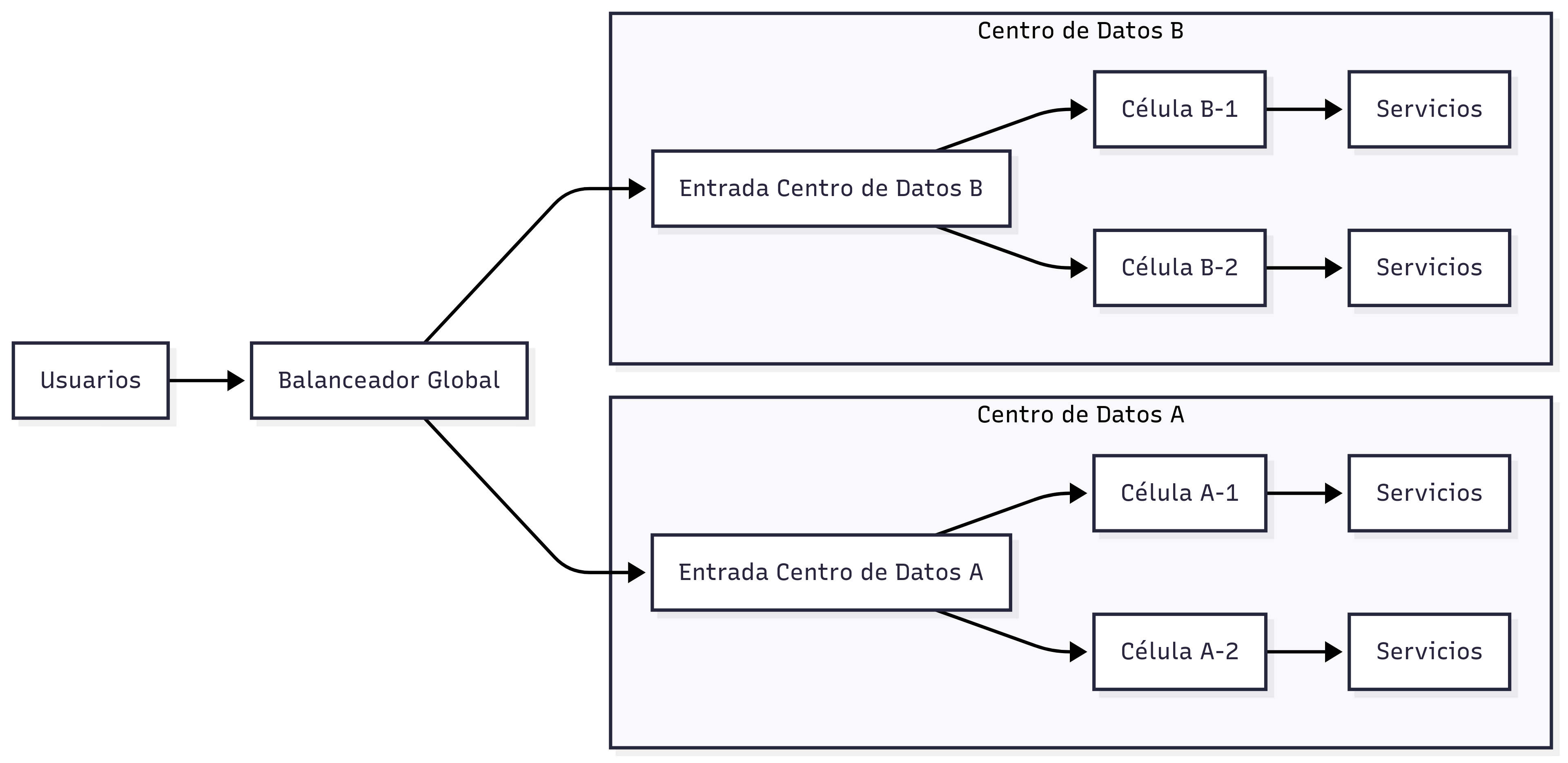
Data centers: de activo-pasivo a activo-activo
¿Para qué sirve? Garantizar continuidad ante desastres de un sitio completo y reducir el tiempo de conmutación.
Cómo funciona
Tras 2021 se construyó un segundo centro de datos en otra región y se operó inicialmente en activo-pasivo. El principal manejaba el tráfico y el secundario quedaba en espera con conmutación manual que podía tardar horas.
El objetivo final es activo-activo con distribución de peticiones basada en latencia, capacidad y salud. El balanceador global permite mover tráfico casi al instante ante degradaciones.
Tecnologías clave
Redundancia geográfica, red privada global, balanceadores globales con chequeos de salud y control de capacidad.
Diagrama de células y centros de datos
Arquitectura celular: tamaño, aislamiento y desechabilidad
¿Para qué sirve? Aislar fallos y limitar su alcance para que no afecten al resto del sistema.
Cómo funciona
Cada centro de datos se divide en células de unas 1.400 máquinas.
Los servicios se despliegan de forma replicada en múltiples células.
Una célula degradada se considera desechable. El tráfico se drena y se redirige a otras células sanas.
La célula afectada se destruye y se reconstruye desde cero con automatización completa.
Tecnologías clave
Infraestructura como Código, contenedores, orquestación con HashiCorp Nomad y service discovery con Consul.
Service mesh y comunicación inteligente
¿Para qué sirve? Gestionar el tráfico entre servicios y entre células con políticas centralizadas para evitar propagación de fallos.
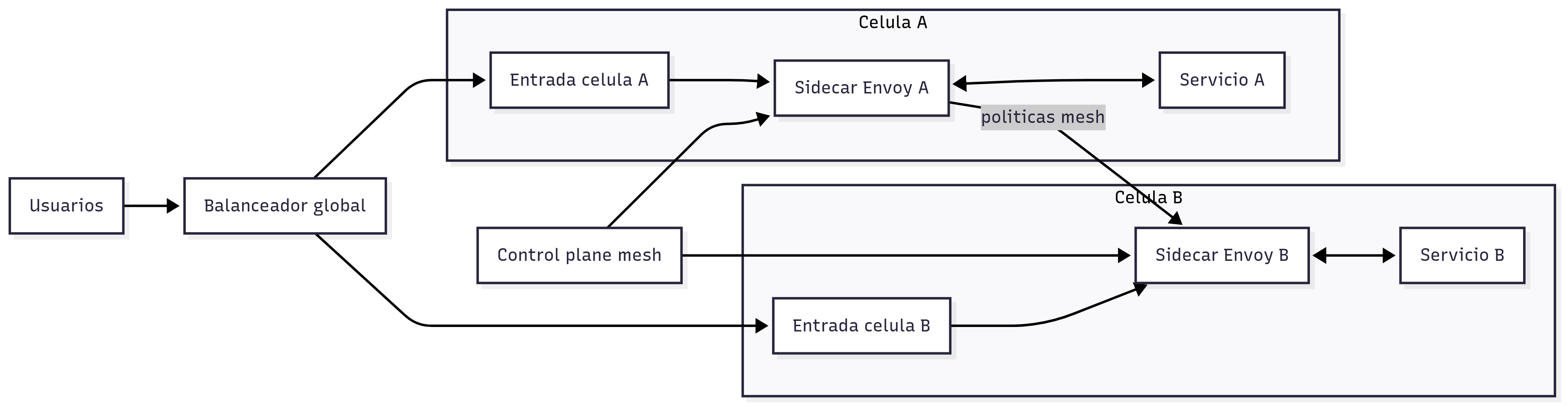
Cómo funciona
Un proxy sidecar como Envoy se despliega junto a cada instancia y controla todo el tráfico de entrada y salida.
El mesh aplica enrutado, reintentos con límites, circuit breakers y control de concurrencia.
El objetivo es mantener afinidad dentro de la misma célula y bloquear patrones de tráfico problemáticos en el borde antes de que crucen células.
Tecnologías clave
Envoy como proxy, eBPF para observabilidad a nivel de kernel y mecanismos de service discovery.
Automatización y tooling
¿Para qué sirve? Gestionar una infraestructura a gran escala de forma segura y validar resiliencia de manera proactiva.
Cómo funciona
Orquestación con la HashiStack. Nomad para planificar cargas de trabajo, Consul para descubrir servicios y Vault para gestionar secretos.
Plataformas internas para el ciclo de vida de microservicios. Desde creación y despliegue hasta observabilidad.
Chaos Engineering con TACO Tuesdays donde se restringe capacidad en producción para descubrir debilidades antes de picos de fin de semana.
Defragmentación a nivel de hardware. Alinear ubicación física de máquinas con células lógicas para que el aislamiento sea también físico.
Tecnologías clave
HashiStack, plataformas de CI y CD personalizadas, herramientas de chaos engineering y automatización de provisionamiento.
Métricas y buenas prácticas de resiliencia
Radio de impacto por célula y por centro de datos.
Reintentos con backoff exponencial y presupuestos de error para evitar tormentas de tráfico.
Timeouts coherentes entre cliente y servidor con límites de concurrencia en puntos críticos.
Circuit breakers en llamadas de mayor fan out y en límites inter célula.
MTTR y MTTD monitorizados con alertas por latencia p95 y p99 y error budget por región.
Lecciones aplicables y checklist
Diseña para contener el fallo. Elige un tamaño de célula que puedas drenar y reconstruir con rapidez.
Asegura afinidad de tráfico. Minimiza saltos entre células y corta patrones de consultas con alto fan out.
Automatiza la recuperación. Todo lo que dependa de intervención manual añade minutos al MTTR.
Practica la resiliencia. Programa game days y limita capacidad de forma controlada para validar supuestos.
Mide lo que importa. Latencias, errores por célula y tasa de reintentos cuentan más que el promedio global.
Preguntas frequentes que me surgieron mientras investigaba
Cómo reduce la arquitectura celular el radio de impacto en producción
Divide el sistema en compartimentos equivalentes y aislados. Si uno falla, los demás siguen sirviendo tráfico. El enrutado evita que peticiones nuevas impacten la célula degradada y permite reconstruirla sin detener todo el sistema.
Qué diferencia práctica hay entre activo-pasivo y activo-activo
En activo-pasivo un sitio sirve tráfico y otro espera conmutación. La conmutación puede requerir pasos manuales. En activo-activo ambos sirven tráfico y el balanceador global mueve carga según salud y latencia. La recuperación es más rápida y la capacidad se aprovecha mejor.
Cuándo usar reintentos con backoff y cuándo cortar con circuit breaker
Reintentos con backoff funcionan ante fallos transitorios y colas breves. Si el servicio está saturado o la latencia se dispara, el circuito debe abrirse para proteger al resto. Conviene poner límites por cliente y por ruta para no amplificar el problema.
Por qué un service mesh ayuda a aislar fallos entre células
El mesh aplica políticas de tráfico coherentes en todo el plano de datos. Puede forzar afinidad intra célula, limitar fan out y bloquear patrones peligrosos antes de cruzar células. Así evita contagio y preserva capacidad útil.
Qué métricas seguir para validar resiliencia por célula
Errores y latencia p95 p99 por célula, tasa de reintentos por cliente, saturación de colas, uso de CPU y memoria en puntos críticos y tiempo de drenado y reconstrucción de una célula completa.
👋 ¿Quieres dominar el System Design?
📚 Referencias:
How We're Making Roblox's Infrastructure More Efficient and Resilient (Roblox Tech Blog)
The Infrastructure Supporting Record-Breaking Experiences (Roblox Tech Blog)
Roblox Builds New Cellular Infrastructure to Improve Gaming Experience (InfoQ)
Roblox Return to Service 10/28-10/31 2021 (Informe oficial de la caída)

📝 Otros artículos de interés




🙏 Una última cosa antes de que te vayas:
Siempre estoy trabajando para hacer esta newsletter aún mejor.
¿Podrías tomarte un minuto para responder una encuesta rápida y anónima?
Nos vemos en el próximo correo,
Fran.