
Cómo CloudFlare Bloquea Bots IA: Arquitectura, Firmas HTTP (RFC 9421) y Status Code 402 para Ingenieros de Software
Este es un playbook técnico para controlar cómo acceden los rastreadores y agentes de IA a tu web: bloquear, permitir o cobrar por acceso (HTTP 402 Pay per Crawl),

La web funcionó durante años con un pacto simple: los buscadores rastrean, indexan y envían tráfico a los sitios. En 2025 ese equilibrio está roto. Los bots de IA consumen contenido para entrenar y responder sin devolver visitas. Cloudflare ha movido el control al borde de la red y ha introducido identidad criptográfica y un nuevo modelo económico. En este artículo explico la arquitectura que hay detrás, cómo se decide quién entra, quién no y quién paga, y qué implicaciones tiene para SEO y para la operación diaria de un sitio a nivel técnico.
Como editor de dos newsletters que pasan los 20.000 lectores, he visto cómo una parte de consultas se resuelve dentro de un LLM, sin clics.
Por qué bloquear bots de IA hoy y qué cambia frente a robots.txt
El fichero robots.txt nació como código de conducta.
Ventaja: era simple y universal.
Problema: dependía de la buena fe del bot.
En 2025, con crawlers de entrenamiento, ese modelo honorífico no basta. Datos recientes de Cloudflare muestran que solo cerca del 37 % de los 10.000 dominios superiores disponen de robots.txt y, de esos, porcentajes de un dígito bloquean agentes de IA muy conocidos como GPTBot o Google-Extended. Además, los ratios de rastreo frente a referidos de plataformas de IA son órdenes de magnitud peores que los de buscadores tradicionales.
Cloudflare ha convertido ese “por favor, no me rastrees” en una política aplicada en el borde. La compañía ve más de 57 millones de peticiones por segundo y usa ese contexto global para puntuar y filtrar tráfico automatizado. Para nuevos dominios, ha virado a un enfoque por permiso, con bloqueo de crawlers de IA sin permiso o compensación como configuración por defecto. En paralelo, ha abierto una vía para cobrar el acceso con HTTP 402.
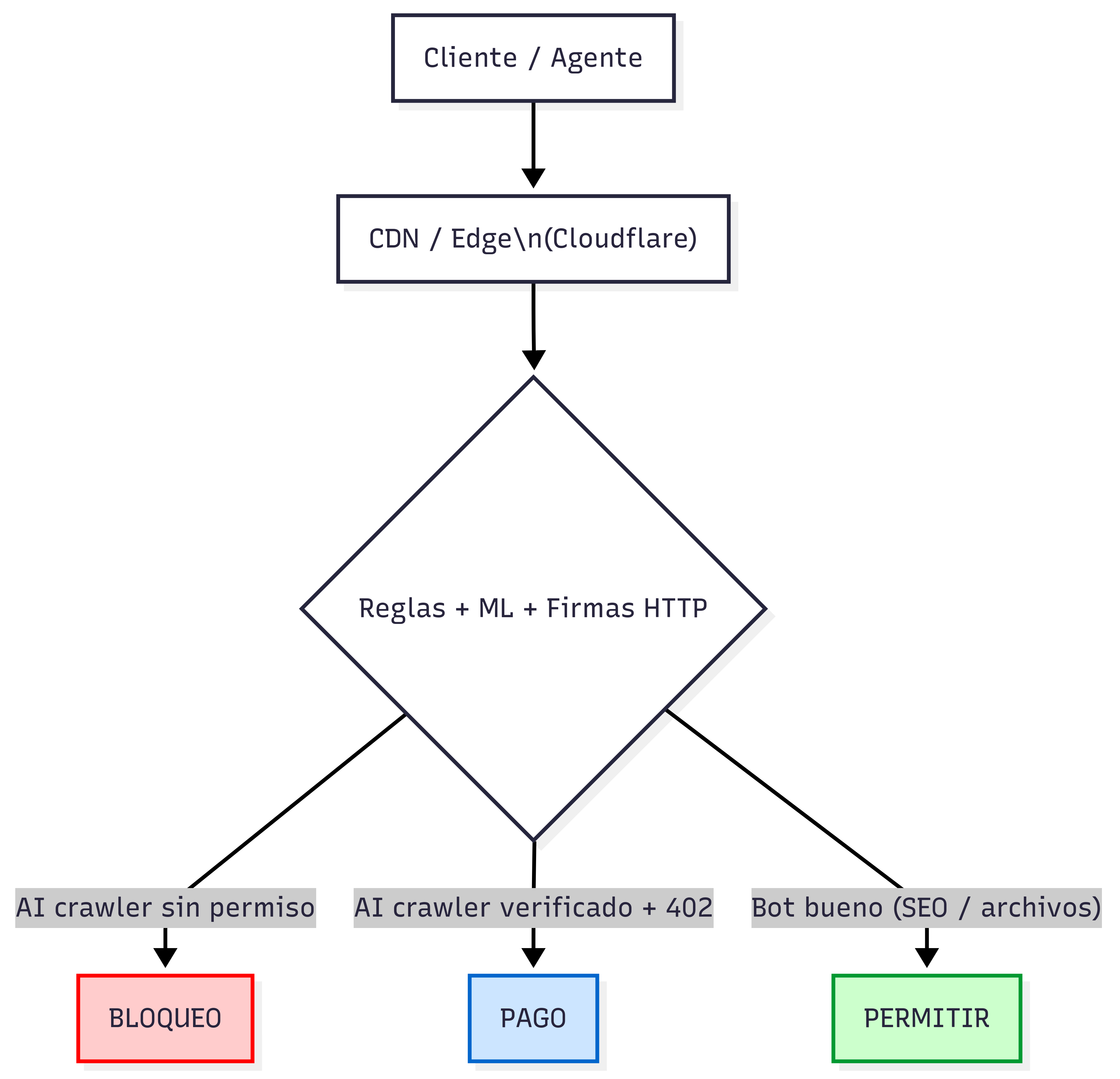
Para los que como yo trabajáis con microservicios o webs en producción, nunca confío en un robots.txt como única barrera. En sitios con picos de tráfico orgánico prefiero la imposición en red con reglas de borde y un robots.txt gestionado de apoyo. Así evito sorpresas si un bot decide ignorar directivas.
Guía rápida: activar el bloqueo de bots de IA sin hacer de “clickops”
Cloudflare mantiene una regla gestionada que bloquea scrapers y crawlers de IA conocidos, actualizada conforme aparecen nuevas huellas. Está disponible para todos los planes y nace de un hallazgo práctico: una regla WAF que reta o bloquea peticiones con puntuación de bot baja corta la inmensa mayoría del scraping, aunque el agente cambie su User-Agent. En sus propios análisis, un umbral en torno a 30 ha resultado efectivo para retar y reducir falsos positivos.
Como recomendación personal, si activáis esto, lo combinaría con una lista de permitidos para bots verificados. Por ejemplo, creo que todos queremos que nuestra página salga en ChatGPT, pero no que nuestro contenido se use para entrenamiento de GPT-6 sin que incluya un link a nuestra web.
Identifica dónde y cómo aplicar IA desde hoy con el GPT Arquitecto IA completamente gratis.
Lo recibes en el primer email que te mando al suscribirte
Reglas WAF con bot score
La detección se apoya en un modelo multicapa: Heurísticas y huellas, detección por JavaScript, anomalías de comportamiento y un modelo global entrenado con el tráfico de la red.
De ese proceso sale un bot score de 1 a 99, donde valores bajos indican alta probabilidad de automatización. Cloudflare recomienda retar a partir de 30 y escalar según resultados.
Ejemplos de reglas expresivas que suelo aplicar por fases:
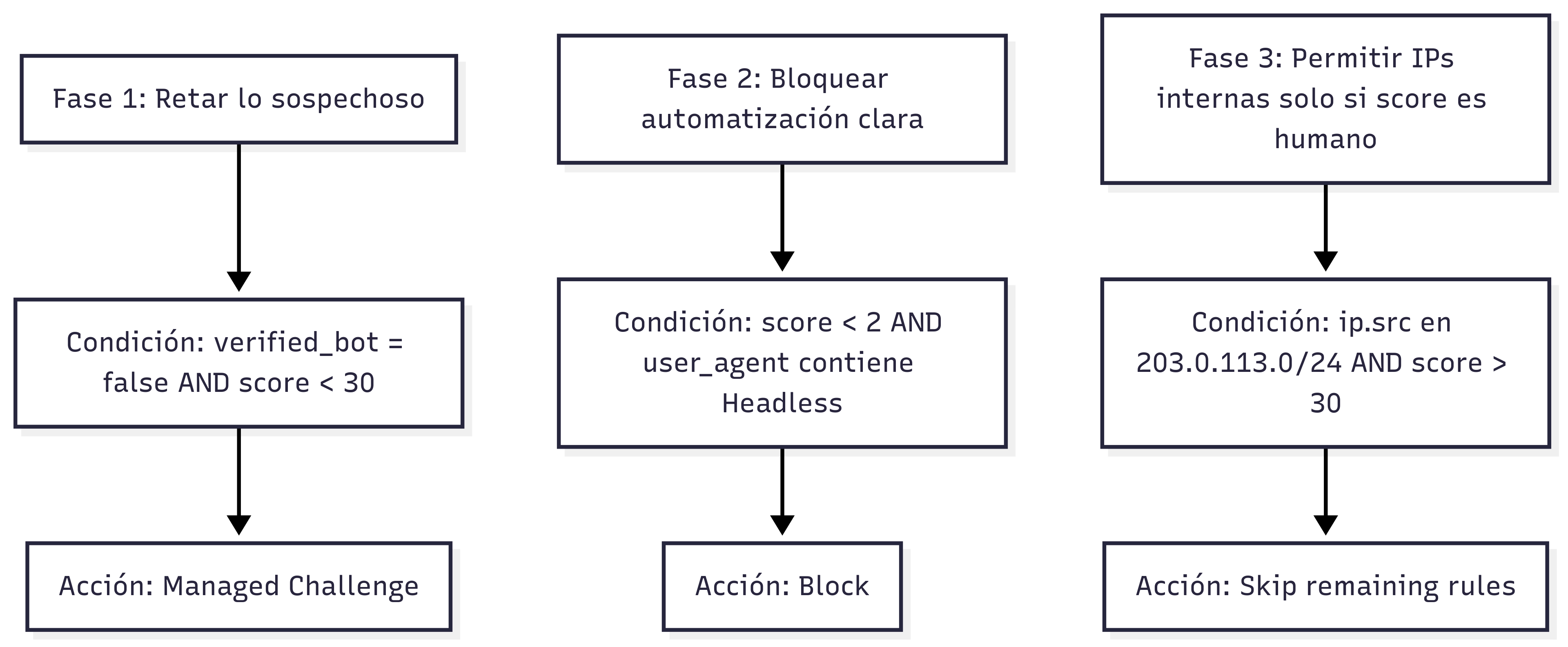
Cloudflare publica plantillas similares que combinan score con condiciones de agente y contexto. Ajusta los umbrales a tu patrón de tráfico y monitoriza respuestas 403 y tasas de resolución de retos.
Robots.txt gestionado: permitir SEO y desautorizar entrenamiento
El robots.txt gestionado por Cloudflare automatiza un mantenimiento que, de forma manual, se vuelve frágil y desactualizado. Inserta directivas de no entrenamiento para agentes como Google-Extended o Applebot-Extended y mantiene tu posicionamiento al no tocar Googlebot. Es un guardarraíl, no un control de acceso, y Cloudflare lo explica explícitamente. Para control real, usa reglas de borde.
Plantilla de ejemplo centrada en entrenamiento, no en indexación:
User-agent: Google-Extended
Disallow: /
User-agent: anthropic-ai
Disallow: /
User-agent: GPTBot
Disallow: /
User-agent: PerplexityBot
Disallow: /
User-agent: Bytespider
Disallow: /
# SEO intacto
User-agent: Googlebot
Allow: /
Sitemap: <https://example.com/sitemap.xml>
Cloudflare ha observado que muchos dominios bloquean GPTBot y olvidan Google-Extended, lo que deja una brecha importante. El robots.txt gestionado corrige esa asimetría y se mantiene al día con el panorama de bots.
Cuando probé a desautorizar solo GPTBot, el efecto fue menor de lo esperado. Añadí Google-Extended y Anthropic y la exposición bajó mucho. Desde entonces prefiero delegar este archivo en la opción gestionada y concentrarme en la imposición a nivel edge.
Bloqueo solo en páginas con anuncios: cuándo y cómo configurarlo
No todos quieren un bloqueo total. Si monetizas con publicidad, puedes bloquear bots de IA únicamente en páginas con anuncios. La detección no es mágica, es ingeniería: el borde parsea el HTML en streaming con un parser de muy baja latencia, busca patrones de unidades de anuncio y recursos de ad servers conocidos. Además, se alimenta de informes CSP de Page Shield para cubrir inserciones dinámicas. Con esas señales, marca hostnames con ads y aplica la política solo donde te da dinero.
Verified Bots y Firmas de mensajes HTTP: identidad criptográfica para crawlers
IP y User-Agent son débiles. La alternativa es que el bot se autentique con una firma criptográfica de la petición. La especificación es HTTP Message Signatures, estandarizada como RFC 9421. Cloudflare la ha integrado en su programa Verified Bots y valida en el borde las cabeceras Signature-Input, Signature y Signature-Agent. Con eso puede marcar una petición como verificada y tú puedes fiarte de que ese “Google-<algo>” realmente es quien dice ser.
Ejemplo formateado a partir de la documentación y ejemplos de Cloudflare:
GET /ruta HTTP/1.1
Host: www.ejemplo.com
User-Agent: Mozilla/5.0
Signature-Agent: "<https://bot-keys.example.org/.well-known/http-message-signature-directory>"
Signature-Input: sig=("@authority" "signature-agent");created=1700000000;expires=1700011111;keyid="ed25519:abcd";tag="web-bot-auth"
Signature: sig=:jdq0SqOwHdyHr9+r5jw3iYZH6aNGKijYp/EstF4RQ...==:
Cloudflare verifica el material de claves publicado en el directorio .well-known/http-message-signature-directory, reconstruye la base de firma con los componentes especificados y valida con Ed25519. Si todo cuadra, marca el tráfico como verificado y puedes crear reglas sobre cf.bot_management.verified_bot o incluso segmentar por categoría de bot verificado.
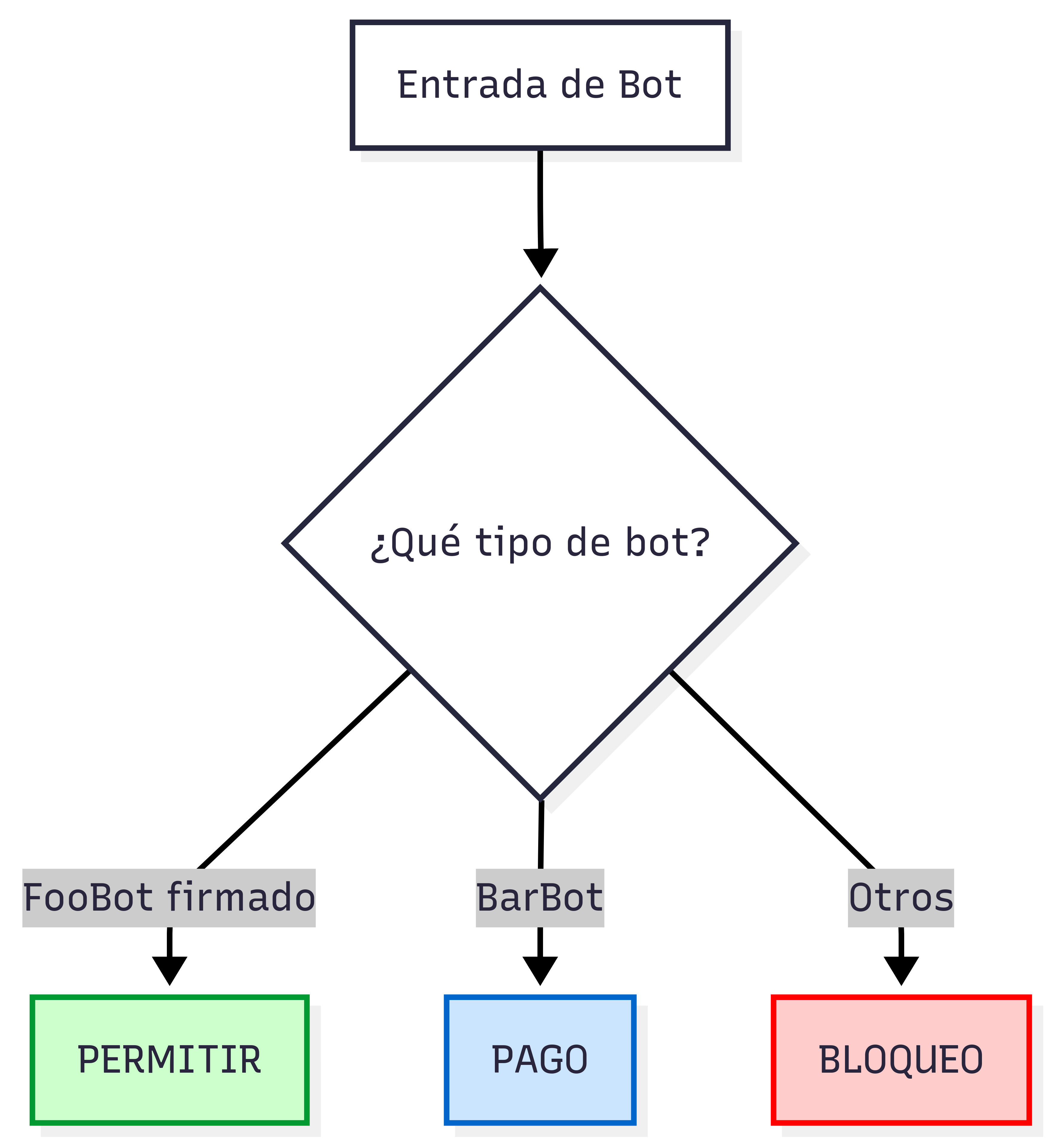
Pay per crawl: cómo funciona el 402 Payment Required y para qué te sirve
Bloquear o permitir ya no son las únicas opciones. Cloudflare ha presentado un modelo de cobro por rastreo que usa el histórico código 402 Payment Required y cabeceras declarativas.

El bot pide un recurso, el borde responde 402 con crawler-price y si el agente acepta, reintenta con crawler-exact-price.
Un flujo proactivo sería que el bot adelanta un crawler-max-price y, si cubre el precio configurado, el borde sirve el 200 con crawler-charged.
Cloudflare actúa como merchant of record, agrega eventos y liquida al editor. Está en beta privada y se integra con la verificación criptográfica para evitar suplantaciones.
Ejemplos de intercambio mínimos:
HTTP/2 402 Payment Required
crawler-price: USD 0.01
# Reintento aceptando el precio exacto
GET /articulo.html
Signature-Agent: "<https://bot-keys.example.org/.well-known/http-message-signature-directory>"
Signature-Input: ...
Signature: ...
crawler-exact-price: USD 0.01
HTTP/2 200 OK
crawler-charged: USD 0.01
Esto abriría un mecanismo para que tu web monetice por salir en los principales resultados de ChatGPT, pero de primeras podría hacer que tuviera menos tráfico porque estos bots de IA decidan no pagar nunca y referenciar webs que sean gratis.
Métricas, pruebas y rollback seguro: cómo validar que todo sigue indexando
Medir es la única forma de operar sin miedo. KPIs recomendados y dónde obtenerlos:
Crawl-to-refer por operador. Cloudflare Radar publica tendencias por bot y sector y la propia plataforma expone AI Insights. Úsalo para decidir a quién bloqueas, a quién cobras y a quién dejas pasar.
Tasa de desafíos resueltos y 403 por ruta. Ajusta umbrales y excepciones con base en ello.
Monitorea errores de indexación en Search Console cuando apliques cambios. Aunque uses robots.txt gestionado, recuerda que robots.txt no bloquea a quien no lo respeta.
Porcentaje de tráfico autenticado como Verified Bot frente a no autenticado. Con firmas, este dato debería subir con el tiempo.
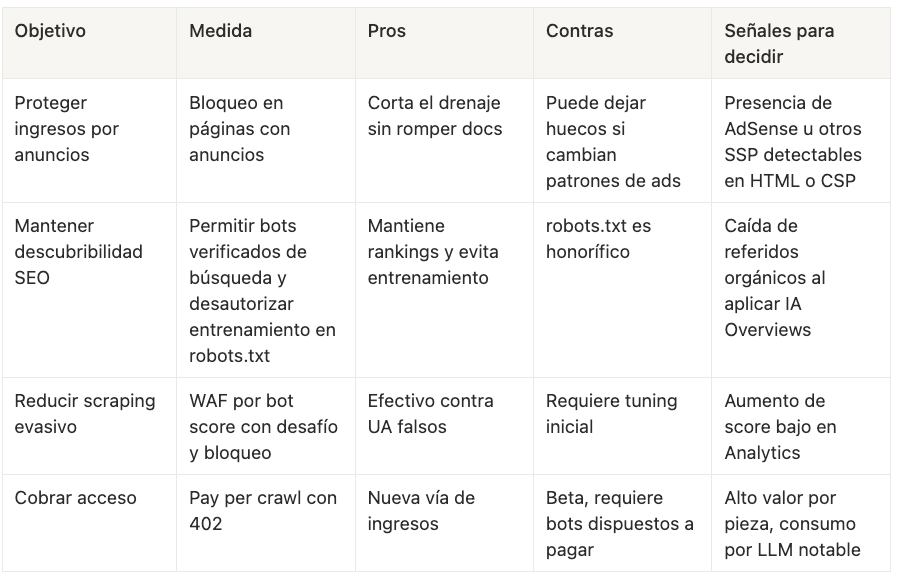
Matriz de decisiones y trade-offs
Caso práctico breve, expresado como política
Política reproducible que he aplicado en un sitio editorial:
robots.txt gestionado activado, con SEO intacto para Googlebot y bloqueo a Google-Extended, Anthropic y GPTBot.
Regla WAF de desafío para
score < 30y bloqueo parascore < 2.Bloqueo en hostnames con anuncios activado, manteniendo docs abiertos.
Bots verificados con firma en allow, basados en RFC 9421 y Web Bot Auth.
Piloto de 402 en piezas evergreen con alta demanda de LLM.
En resumen
La emergencia de los motores de respuestas de IA ha roto el modelo económico fundamental de la web abierta. En respuesta, ha surgido una nueva arquitectura de control y monetización:
El antiguo pacto de valor, basado en el tráfico referido por los motores de búsqueda, ya no es funcional.
El mecanismo tradicional de
robots.txt, basado en un sistema de honor, es insuficiente para gestionar a los scrapers de IA.La solución arquitectónica pasa por mover la imposición de políticas al borde de la red (edge), donde se puede actuar a escala global.
La identificación de bots se basa en un sistema multicapa que combina heurísticas, machine learning y criptografía para una precisión máxima.
Las Firmas de Mensajes HTTP (RFC 9421) crean una identidad digital verificable para los bots, un pilar para las interacciones de confianza.
La iniciativa "Pay per crawl", utilizando el código de estado
HTTP 402, establece las bases para una economía programática donde el contenido se paga directamente.El objetivo final es reestablecer un intercambio de valor justo que incentive la creación de contenido original y de alta calidad, asegurando la sostenibilidad de la web abierta
👋 PD – ¿Quieres dominar el system design?
Preguntas que yo mismo me he hecho escribiendo este artículo
Cómo bloqueo GPTBot sin romper SEO
Usa robots.txt gestionado para expresar tu política de no entrenamiento y una regla WAF por score para imponerla a quienes ignoren robots.txt. Mantén permitidos bots verificados de búsqueda.
Qué diferencia hay entre Googlebot y Google-Extended
Googlebot indexa y trae tráfico. Google-Extended se usa para entrenamiento de modelos. Puedes permitir el primero y desautorizar el segundo en robots.txt.
Cuándo usar bloqueo por anuncios en lugar de bloqueo total
Cuando la prioridad es proteger ingresos publicitarios sin cerrar docs o páginas de soporte. El borde detecta anuncios inspeccionando HTML y señales CSP y aplica la política solo en esos hostnames.
Por qué cf.bot_management.score 30 es un buen umbral inicial
Porque reduce falsos positivos y captura crawlers que intentan camuflarse con User-Agents cambiantes. Cloudflare lo recomienda en sus análisis y documentación. Ajusta con datos de tu tráfico.
Qué garantías tengo de que un bot verificado es auténtico
Firmas de mensajes HTTP según RFC 9421. El bot firma con su clave privada, publica sus claves públicas en un directorio bien conocido y Cloudflare valida la firma en el borde.
👋 PD – ¿Quieres dominar el system design?
📚 Referencias
Visión general y cambio de política: Content Independence Day: no AI crawl without compensation!
Detalles de la iniciativa de monetización: Introducing pay per crawl
Identidad criptográfica para bots: Verified Bots with Cryptography (HTTP Message Signatures)

📝 Otros artículos de interés




👏 Aplauso semanal
Aquí algunos artículos que me han gustado esta última semana:
12 herramientas top para arrancar potente en Septiembre de Daniel Primo . Una lista de herramientas que van desde asistentes de programación hasta soluciones de backend y automatización
Noticias de la semana 15.09.25 de Marcia Villalba . Lista de noticias cada semana sobre AWS y serverless. Lo más interesante para mí el lanzamiento de Amazon Bedrock AgentCore para desplegar agentes de IA.
Cuando alguien rompe a llorar... ¿Manager o psicólogo? de José Carlos Gil . Los managers no son terapeutas, pero sí deben dominar los “primeros auxilios emocionales”.
🙏 Una última cosa antes de que te vayas:
Siempre estoy trabajando para hacer esta newsletter aún mejor.
¿Podrías tomarte un minuto para responder una encuesta rápida y anónima?
Nos vemos en el próximo correo,
Fran.